Bryan Drewery
2018-04-25 19:41:37 UTC
back trace at:Â Loading Image...
If anyone wants to take a look..
In the exit syscall, while deallocating a vm object.
I haven't see references to a similar crash in the last 10 days or so..
But if it rings any bells...
I just hit this on r332455 and have a dump.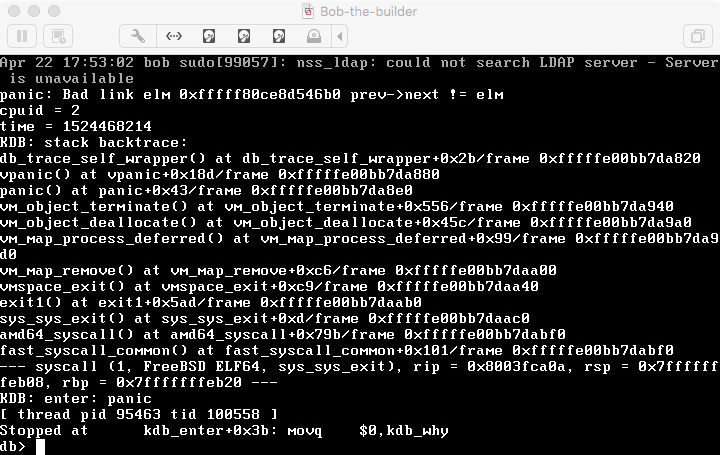
If anyone wants to take a look..
In the exit syscall, while deallocating a vm object.
I haven't see references to a similar crash in the last 10 days or so..
But if it rings any bells...
panic: Bad link elm 0xfffff811cd920e60 prev->next != elm
cpuid = 10
time = 1524682939
db_trace_self_wrapper() at db_trace_self_wrapper+0x2b/frame 0xfffffe23f450c3b0
vpanic() at vpanic+0x18d/frame 0xfffffe23f450c410
panic() at panic+0x43/frame 0xfffffe23f450c470
vm_object_destroy() at vm_object_destroy/frame 0xfffffe23f450c4d0
vm_object_deallocate() at vm_object_deallocate+0x45c/frame 0xfffffe23f450c530
vm_map_process_deferred() at vm_map_process_deferred+0x99/frame 0xfffffe23f450c560
vm_map_remove() at vm_map_remove+0xc6/frame 0xfffffe23f450c590
exec_new_vmspace() at exec_new_vmspace+0x185/frame 0xfffffe23f450c5f0
exec_elf64_imgact() at exec_elf64_imgact+0x8fb/frame 0xfffffe23f450c6e0
kern_execve() at kern_execve+0x82c/frame 0xfffffe23f450ca40
sys_execve() at sys_execve+0x4c/frame 0xfffffe23f450cac0
amd64_syscall() at amd64_syscall+0x786/frame 0xfffffe23f450cbf0
fast_syscall_common() at fast_syscall_common+0x101/frame 0xfffffe23f450cbf0
--- syscall (59, FreeBSD ELF64, sys_execve), rip = 0x800d7af7a, rsp = 0x7fffffffbd28, rbp = 0x7fffffffbe70 ---
cpuid = 10
time = 1524682939
db_trace_self_wrapper() at db_trace_self_wrapper+0x2b/frame 0xfffffe23f450c3b0
vpanic() at vpanic+0x18d/frame 0xfffffe23f450c410
panic() at panic+0x43/frame 0xfffffe23f450c470
vm_object_destroy() at vm_object_destroy/frame 0xfffffe23f450c4d0
vm_object_deallocate() at vm_object_deallocate+0x45c/frame 0xfffffe23f450c530
vm_map_process_deferred() at vm_map_process_deferred+0x99/frame 0xfffffe23f450c560
vm_map_remove() at vm_map_remove+0xc6/frame 0xfffffe23f450c590
exec_new_vmspace() at exec_new_vmspace+0x185/frame 0xfffffe23f450c5f0
exec_elf64_imgact() at exec_elf64_imgact+0x8fb/frame 0xfffffe23f450c6e0
kern_execve() at kern_execve+0x82c/frame 0xfffffe23f450ca40
sys_execve() at sys_execve+0x4c/frame 0xfffffe23f450cac0
amd64_syscall() at amd64_syscall+0x786/frame 0xfffffe23f450cbf0
fast_syscall_common() at fast_syscall_common+0x101/frame 0xfffffe23f450cbf0
--- syscall (59, FreeBSD ELF64, sys_execve), rip = 0x800d7af7a, rsp = 0x7fffffffbd28, rbp = 0x7fffffffbe70 ---
--
Regards,
Bryan Drewery
Regards,
Bryan Drewery